Wir freuen uns, die neueste Version von SeaTable vorzustellen! Das Release ist zwar nur ein “Minor” Release, kommt aber ganz groß daher. Das erweiterte Seitendesign Plugin bietet nun mehr Optionen, um anspruchsvolle Vorlagen zu gestalten und zu verwalten. Neue Funktionen erlauben darüber hinaus ganz neue Einsatzszenarien. Das gleich tut auch das Big Data Backend, das mit der Version 3.1 Produktivreife erhält. Das Enterprise Feature sprengt SeaTables bisheriges Limit von 100.000 Zeilen pro Base und macht SeaTable damit bereit für größere Aufgaben. Größere Teams werden sich über die Möglichkeit freuen, Gruppen auf der Homepage sortieren und Ansichten in Bases kategorisieren zu können. Diese Highlights und ein paar weitere Neuerungen stellen wir in hier vor. Das Changelog enthält die vollständige Liste der Änderungen.
Die neuen Funktionen stehen ab sofort auf SeaTable Cloud zur Verfügung. Das letzte Build von SeaTable 3.1 wurde heute Morgen installiert. Selbsthoster können SeaTable 3.1 vom bekannten Docker Repository runterladen.
Schneller, schönere Listen und Dokumente
Dem überarbeiteten Seitendesign Plugin könnte man eine eigene Veröffentlichung widmen, so vollgepackt mit neuen Funktionen präsentiert es sich in SeaTable 3.1. Da wären die Listendruckfunktion, die dynamischen Felder inkl. Kopf- und Fußzeile sowie die Versionierungsfunktion. Die Seitenleiste im Bearbeitungsmodus hat sich dadurch deutlich gefüllt (siehe Abbildung unten). Ach und die Vorlagen im Plugin lassen sich nun auch in der Übersicht verschieben und sortieren. Aber nun alles der Reihe nach.
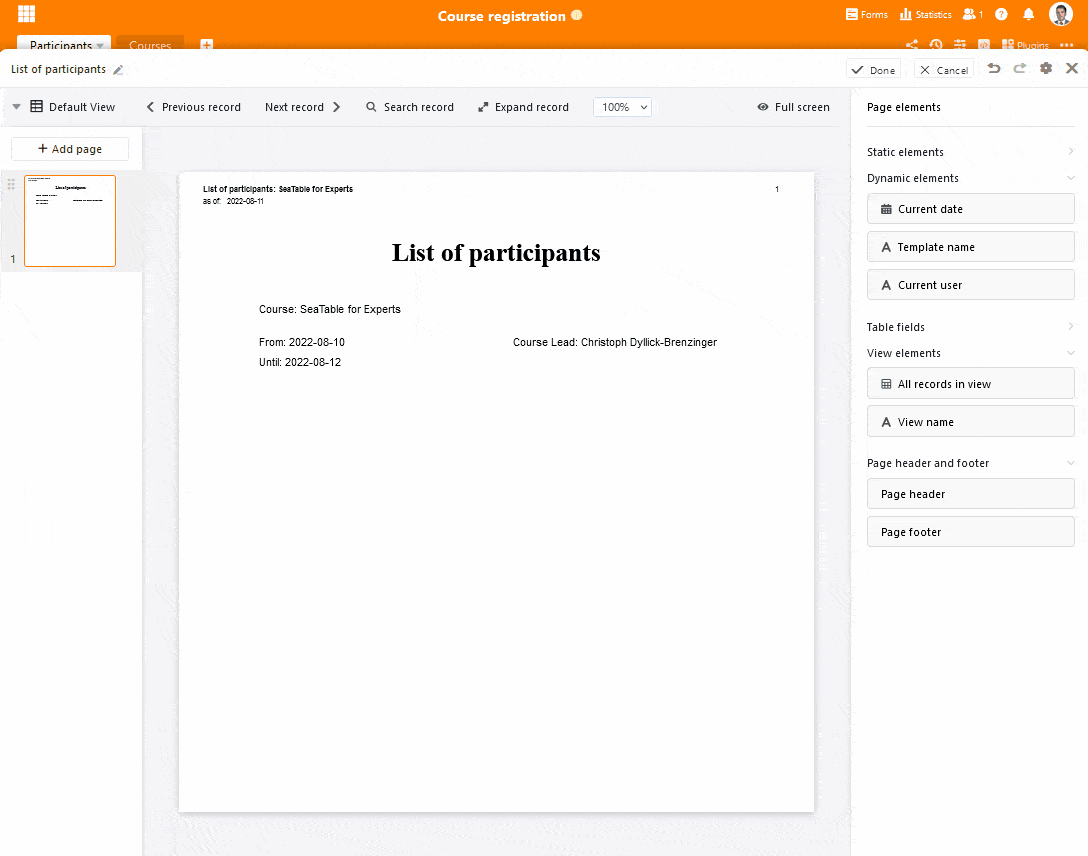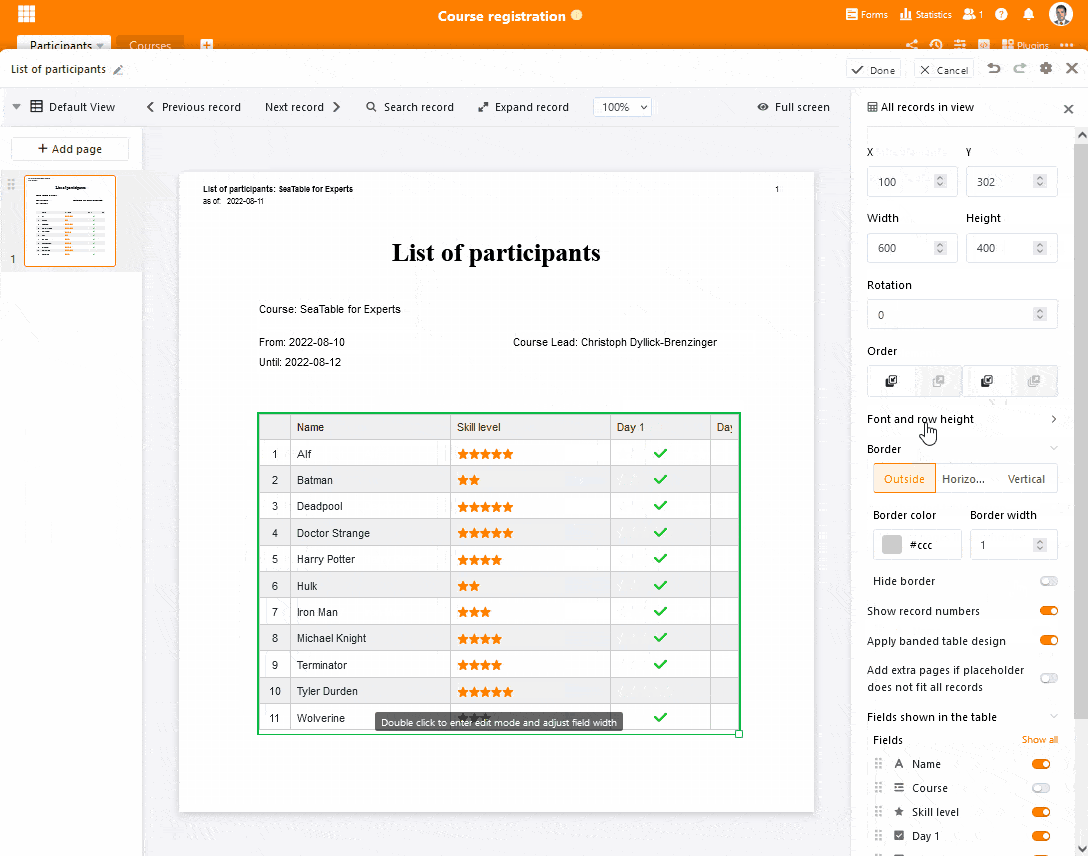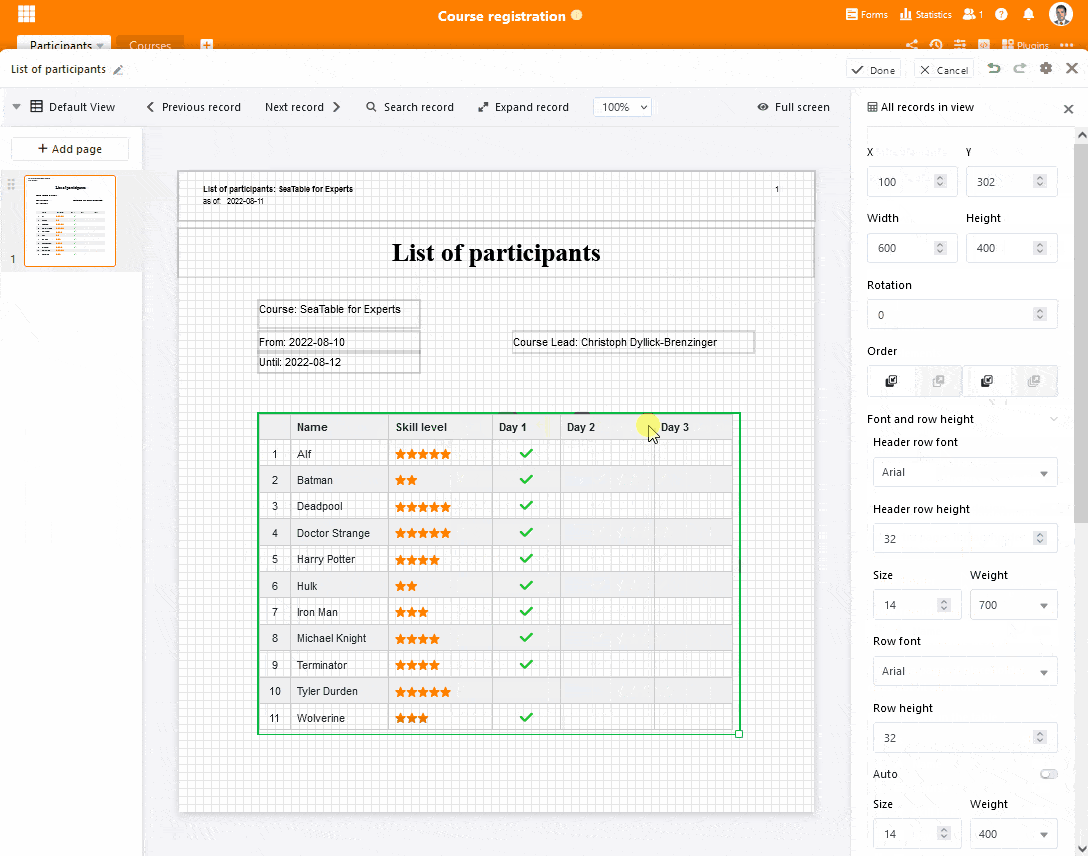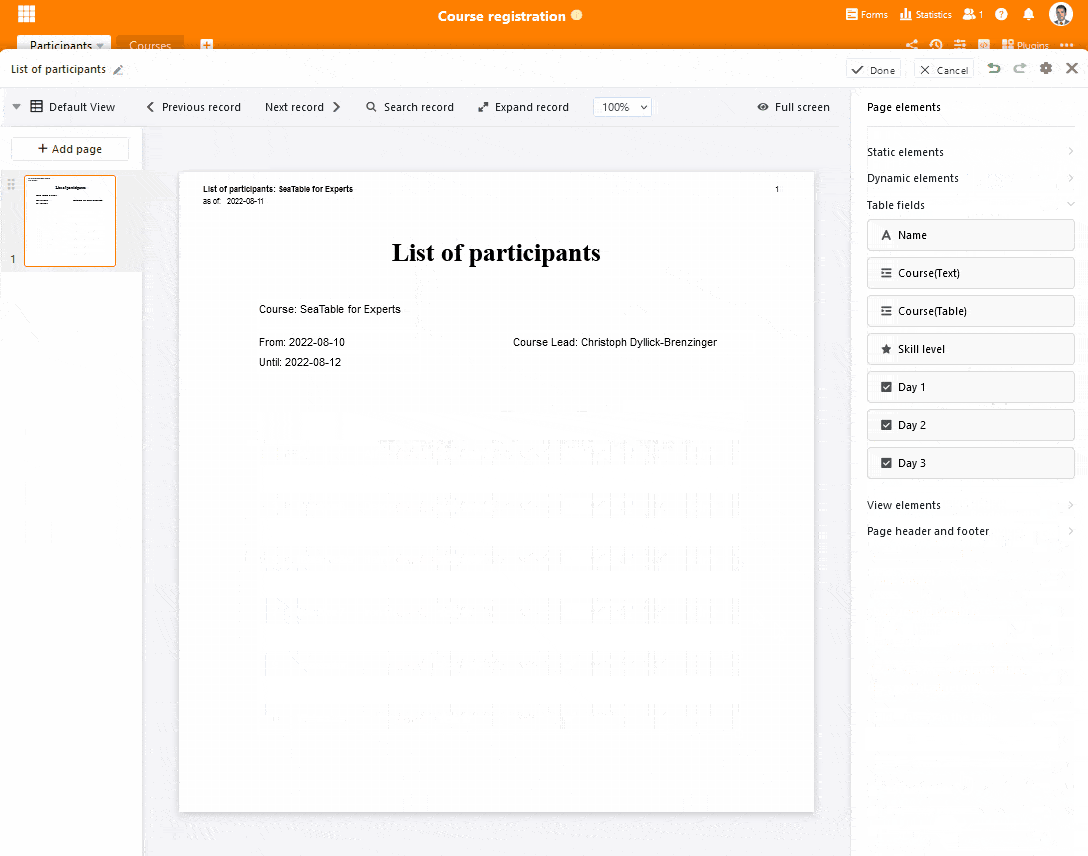
Die neue Listendruckfunktion bringt den Inhalt einer Ansicht im Nullkommanix in einem ansprechenden Design auf Papier bzw. in ein PDF-Dokument. Ziehen Sie einfach das Element “Alle Einträge der Ansicht” auf die Vorlage, passen Sie die Größe des Platzhalters an, formatieren Sie die Tabelle nach Ihren Vorlieben und ergänzen Sie die übrigen Seitenelemente wie z.B. Dokumententitel, Logo und Datum. SeaTable kümmert sich dann beim Druck automatisch um das Tabellenlayout und den Seitenumbruch, wenn die Zeilen der gewählten Ansicht nicht in den Platzhalter passen. SeaTable ergänzt dafür so viele Seiten wie nötig.
Mit den dynamischen Feldern lassen sich nun ganz einfach kontextbezogene Informationen auf einer Seite einfügen. Konkret sind dies das aktuelle Datum, die verwendete Vorlage, der aktuelle Benutzer und die Seitenzahl. In der Nutzung unterscheiden sich dynamische Felder nicht von statischen Textfeldern. Auch die Formatierungsoptionen sind identisch. Einfach das Feld auf die Vorlagen ziehen, korrekt positionieren und formatieren – SeaTable kümmert sich um den Rest.
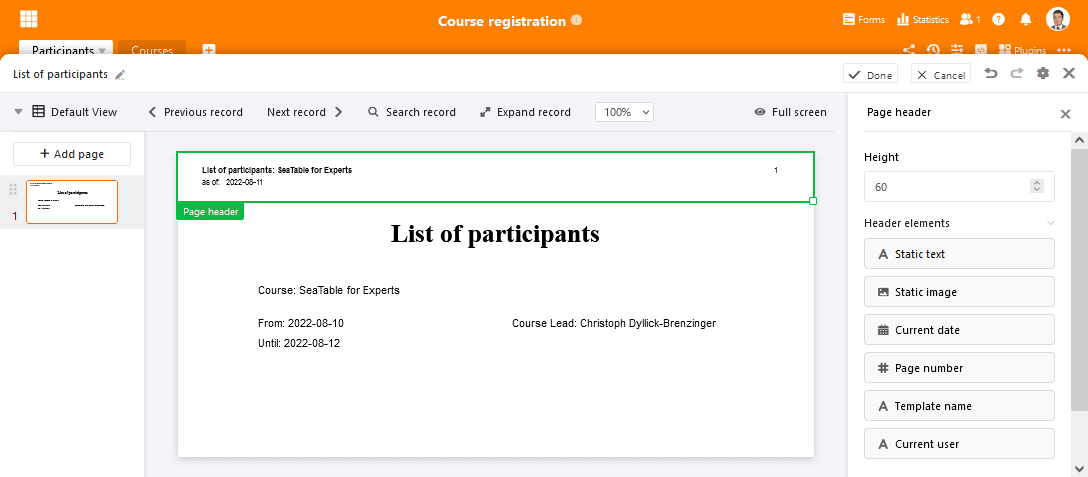
Eine ideale Ergänzung für die dynamischen Elemente sind die neuen Kopf- und Fußzeilen. Elemente, die dort platziert werden, werden auf jeder Seite wiederholt, selbstverständlich inklusive auf den Seiten, die das Plugin beim Listendruck automatisch ergänzt. Und nicht nur dynamische Elemente können in Kopf- und Fußzeile verwendet werden. Auch die beiden Felder statischer Text und statisches Bild lassen sich einbetten, um Dokumente mit aussagekräftigen Metainformationen zu versehen.
Bei der Nutzung all dieser Neuerungen kann es natürlich mal vorkommen, dass man seine Vorlage etwas durcheinanderbringt und gerne zu einem früheren Zustand zurückspringen möchte. Die Versionierung, über die das Seitendesign Plugin mit dieser Version verfügt, macht genau das möglich. Bei jeder Speicherung der Vorlage erstellt das Plugin einen Snapshot, auf den Sie zurückspringen können. Wenn Ihnen gemachte Änderungen an der Vorlage nicht gefallen, dann sind diese mit einem Klick wieder rückgängig gemacht. Bei der Wiederherstellung einer früheren Version wird die aktuelle Vorlage durch die frühere Version ersetzt. Natürlich bleiben alle anderen Versionsstände dabei erhalten.
Lust bekommen, das neue Seitendesign Plugin auszuprobieren? Na dann los! Die Verbesserungen stehen in allen SeaTable Cloud Abonnements und in SeaTable Server Developer und Enterprise Edition zur Verfügung.
Adieu Zeilenlimit (nur für Enterprise Abos)
Wenn Sie sich bisher Sorgen gemacht haben, dass Ihnen SeaTables Limit von 100.000 Zeilen pro Base in absehbarer Zukunft Probleme bereiten könnte, dann haben Sie ab sofort eine Sorge weniger. Mit dem neuen Big Data Backend können Sie Millionen von Zeilen in einer SeaTable Base speichern. Damit bietet SeaTable nicht nur ein viel höheres Zeilenlimit als seine unmittelbare Konkurrenz, sondern stößt auch in Regionen vor, die bisher klassischen SQL-Datenbanken vorbehalten waren. Sie suchen eine Datenbank mit REST API, integrierter Skriptunterstützung, Automationen und/oder graphischen Frontend mit Echtzeit Kollaboration, dann brauchen Sie jetzt nicht mehr weitersuchen.
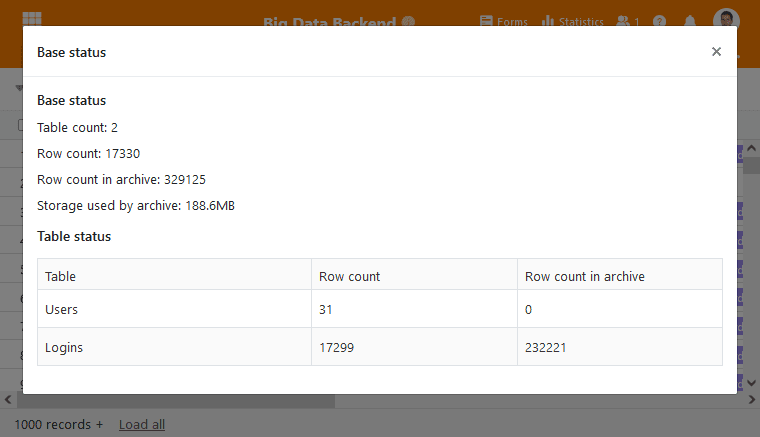
Die bisherige Größenbegrenzung war notwendig, da SeaTable eine Base vollständig in den Arbeitsspeicher laden muss, um gleichzeitig, gemeinsam in einer Base zu arbeiten. Mit der Aktivierung der Big Data Funktion ist dies nicht mehr so. Die Big Data Funktion teilt die Daten in einer Base auf: Datensätze, die automatisch beim Öffnen einer Base geladen werden, und solche Datensätze, die nur bei expliziter Abfrage — neudeutsch on-demand — geladen werden, z.B. bei einer Filterung oder einer statistischen Auswertung über alle Datensätze. Werden also nur die automatisch geladenen Daten verwendet, dann beeinflussen auch Millionen von Datensätzen im Big Data Speicher nicht die Ladezeiten einer Base oder deren Speicherbedarf.
Mit dieser Zweiteilung der Daten gewinnen Sie als Benutzer enorme zusätzliche Flexibilität. Kollaborative Projekte, bei denen die Teammitglieder im Webinterface arbeiten, lassen sich ebenso umsetzen, wie datenintensive Anwendungen mit automatisierter Datenerfassung. Da die Datensätze im Big Data Speicher keine Online-Kollaboration unterstützen, d.h. Änderung an Daten werden nicht an andere Benutzer gepusht, sondern erst nach einem erneuten Abruf sichtbar, eignet sich dieser Speicher insbesondere für Datensätze, an denen keine aktive Arbeit stattfindet. Dies erklärt auch, warum die Beta der Big Data Funktion in SeaTable 2.3 noch unter dem Namen Archiv erschien.
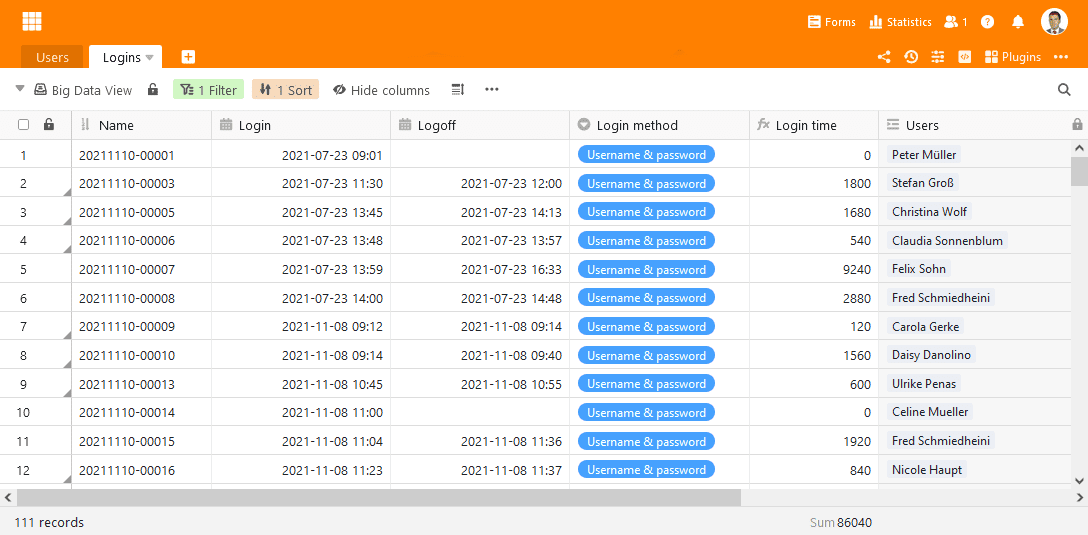
Datensätze im Big Data Backend unterstützen alle Spaltentypen und können geändert und gelöscht, gefiltert und gruppiert werden. Datensätze können auch zwischen normalen und Big Data Speicher hin- und hergeschoben werden. Andererseits bleiben die Bearbeitungsmöglichkeiten für Big Data Datensätze technisch bedingt hinter denen im normalen Speicher zurück. Einschränkungen gibt es insbesondere bei der Freigabe, Automationen und Plugins: Ansichten, die Daten des Big Data Backends inkludieren, können nicht geteilt werden. Auch kann nur das Statistik Plugin mit Datensätzen im Big Data Speicher umgehen. Alle anderen Plugins und auch Automationen können nur normale Ansichten verwenden. Big Data Datensätze können auch nicht verknüpft werden. Ist das erforderlich, dann müssen sie zunächst in den normalen Speicher verschoben werden.
| Normale Ansicht | Big Data Ansicht | |
|---|---|---|
| Kollaboratives Arbeiten | ✓ | |
| Unterstützung aller Plugins | ✓ | |
| Unterstützung aller Spaltentypen | ✓ | ✓ |
| Sortierung | ✓ | ✓ |
| Filterung | ✓ | ✓ |
| Gruppierung | ✓ | ✓# |
| Ausblenden | ✓ | ✓ |
| Bedingte Formatierung | ✓ | |
| Suche | ✓ | ✓ |
| Suche & Ersetzen | ✓ | |
| Datenverarbeitung | ✓ | |
| Export to Excel | ✓ | ✓ |
| Export to DTABLE | ✓ |
# Diese Funktion ab SeaTable 3.2 zur Verfügung stehen.
Der Big Data Speicher muss in einer Base über die Einstellungen aktiviert werden. Der Transfer von Daten aus dem normalen in den Big Data Speicher erfolgt über die Funktion “Ansicht archivieren”. Der Inhalt des Big Data Speichers lässt sich in einer Big Data Ansicht anzeigen. Big Data Ansichten laden zusätzlich zu den Datensätzen im normalen Speicher auch Daten aus dem Big Data Speicher. Zunächst lädt die Ansicht nur 1.000 Zeilen aus dem Big Data Speicher. Diese sind im Tabelleneditor am grauen Dreieck in der Zeilennummernspalte erkennbar. Über das Kontextmenu lassen sich solche Zeilen wieder in den normalen Speicher verschieben. Um weitere Big Data Zeilen anzuzeigen, scrollen Sie über das Ende der Tabelle hinaus oder klicken Sie auf “Alle Laden” in der Statuszeile.
Mehr Übersicht in großen Teams
Bei großen Teams mit vielen Benutzern kann es schon mal etwas unübersichtlich werden. In Bases konkurrieren eine große Anzahl an Ansichten um Aufmerksamkeit und auf der Homepage sammeln sich Dutzende Gruppen mit ebenso vielen Bases, so dass der Fokus aufs wesentliche verloren geht.
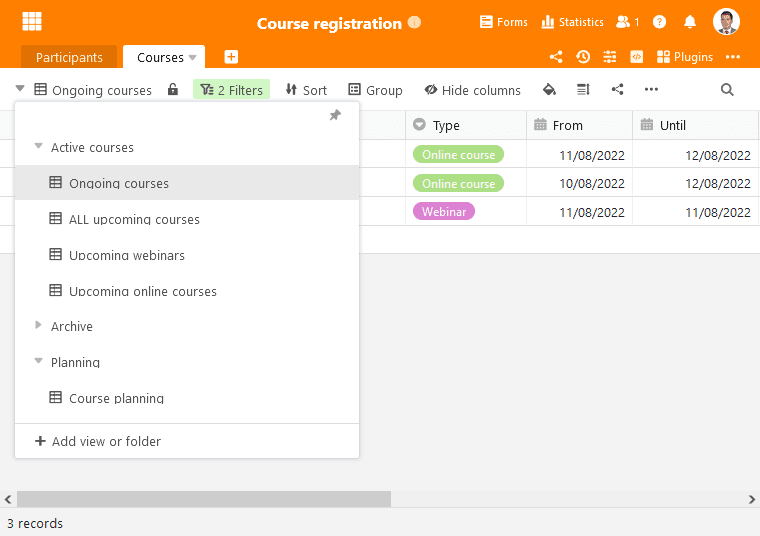
In Bases lassen sich mit der neuen Version nun Ansichten in Ordnern zusammenfassen und so Übersichtlichkeit zurückgewinnen. Einen Ordner erstellen Sie genauso wie eine Ansicht. Per Drag & Drop können Sie dann Ansichten in den neuen Ordner verschieben. Bei der Erstellung des ersten Ordners wird ein weiterer Ordner “Mehr Ansichten” erstellt, in den alle bestehenden Ansichten einsortiert werden.
Um mehr Übersicht auf die Homepage zu bringen, lassen sich Gruppen mit SeaTable 3.1 nun in eine Wunsch-Reihenfolge bringen. Neben dem Gruppennamen in der Navigation auf der linken Seite erscheint das bereits von Ansichten bekannt Icon zum Verschieben. Nutzen Sie dieses, um wichtige Gruppen nach oben und solche, die Sie selten benutzen, nach unten zu verschieben. So haben Sie schneller Zugriff auf die entscheidenden Bases. Eine Funktion, mit der sich die Gruppe einklappen lässt, so dass die Bases nicht angezeigt werden, werden wir in Zukunft ergänzen.
Und noch viel mehr
Dieses große kleine Update umfasst noch viele weitere Verbesserungen und Neuerungen, die wir nachfolgend nur kurz darstellen.
Über eine Schaltfläche im gleichnamigen Spaltentyp lassen sich nun auch E-Mails mit Anhang versenden. Auch wurden im Backend alle Vorbereitungen getroffen, um in Zukunft formatierte E-Mails zu versenden. Die Arbeiten im Frontend werden in einem der nächsten Releases abgeschlossen.
Formatierter Text war bis zuletzt der einzige Spaltentypen, der sich nicht filtern ließ (abgesehen vom Spaltentyp Schaltfläche). Mit dem nun eingeführten Leer- bzw. Ist-nicht-Leer Filter wird dieses Defizit beseitigt.
Das Kalender Plugin präsentiert sich nun wie die anderen Plugins über die ganze Breite des Bildschirms und bietet damit mehr Platz.
Außerdem haben wir uns nochmals die Import- und Exportfunktionen angeschaut. Ziel war es, den Excel Import weiter zu verbessern, was uns aus unserer Sicht gut geglückt ist. Außerdem haben wir externe Apps in den DTABLE-Export aufgenommen, womit eine manuelle Nachkonfiguration bei der Migration von Bases unnötig wird.
Bei einem Blick auf den Changelog fällt auch auf, dass viel Arbeit in die Universal App und das Workflow Modul gesteckt wird. Diese werden in naher Zukunft veröffentlicht. Es wird also nicht langweilig!

„*“ zeigt erforderliche Felder an
